Even when I read the title of this post, I ask myself: “Why would anyone want to do that?” 🤣 Trust me, it’s more useful than you might expect.
The story is simple. I was evaluating a migration from one Docker Registry service (Artifactory ) to another (Harbor ). In theory, both work fine as Docker registries, but each has pros and cons (details don’t really matter here).
Since I had both services available, I wanted to see if the new one could at least match-or hopefully outperform-the old one. I could have written a quick script to run a few pulls, but then I remembered a CLI tool: hyperfine1. I hadn’t really used it before, so I gave it a try. To my surprise, it turned out to be perfect for this task.
Running benchmarks
hyperfine \
--prepare 'docker system prune -f -a' \
--runs 5 \
-L registry docker.io,quay.io/centos \
'docker pull {registry}/centos:centos7'
Here’s what’s happening:
--prepare- runs before each benchmark to clear Docker caches, keeping results comparable.-L registry ...- defines variables so I can benchmark different values in one go. Killer feature!--runs 5- runs each variant 5 times.docker ...- the actual command being tested.
In this example, it runs two benchmarks (one for each registry) and compares the results. The output looks like this:
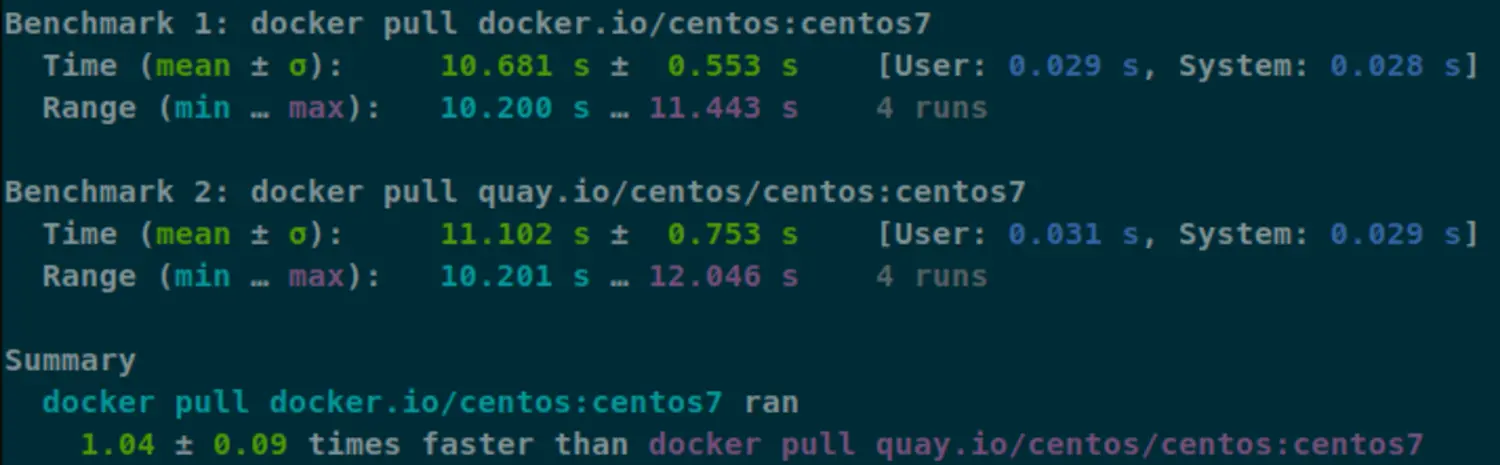
Benchmark 1: docker pull docker.io/centos:centos7
Time (mean ± σ): 10.681 s ± 0.553 s [User: 0.029 s, System: 0.028 s]
Range (min … max): 10.200 s … 11.443 s 4 runs
Benchmark 2: docker pull quay.io/centos/centos:centos7
Time (mean ± σ): 11.102 s ± 0.753 s [User: 0.031 s, System: 0.029 s]
Range (min … max): 10.201 s … 12.046 s 4 runs
Summary
docker pull docker.io/centos:centos7 ran
1.04 ± 0.09 times faster than docker pull quay.io/centos/centos:centos7
I used public registries here so you can copy/paste the command and try it yourself. In my real tests, of course, I used private registry URLs.
Yes, I know this isn’t a very scientific test. It mostly reflects network speed. Still, for a quick reality check, it was surprisingly useful. You can also run it from multiple machines to create higher load while still collecting results.
Over the years I’ve written dozens of tiny benchmarking scripts for tasks like this. Thanks to hyperfine, I don’t need to anymore!
Enjoyed?
![]()